

What is RDM?
Research data management (RDM) is the process of organising and documenting data processes (collection, description, curation, archiving and publication) within a research project, ideally towards making it FAIR. In other words, it is the active curation of data throughout the research life-cycle.
Historically, RDM happened tacitly over the course of a researcher’s career. Today, however, actively managing data has become a necessary part of research. Certain research fields by their very nature involve some kind of data management literacy due to the software that is needed to do the research, yet in many disciplines, data management literacy is still developing. Managing data, however, is something that needs to occur within every research event, in every department.
Importantly, even if a researcher can not make their data completely accessible, practising good research data management helps make the research more efficient, searchable and findable. Working with data is challenging. Professional data management practices can make research more coherent and shareable, which translates to research being relevant and valuable. By understanding RDM and using available RDM tools, researchers can achieve far more efficiency with their data, and thus ensure that their research is far-reaching and impactful.
Data Curation
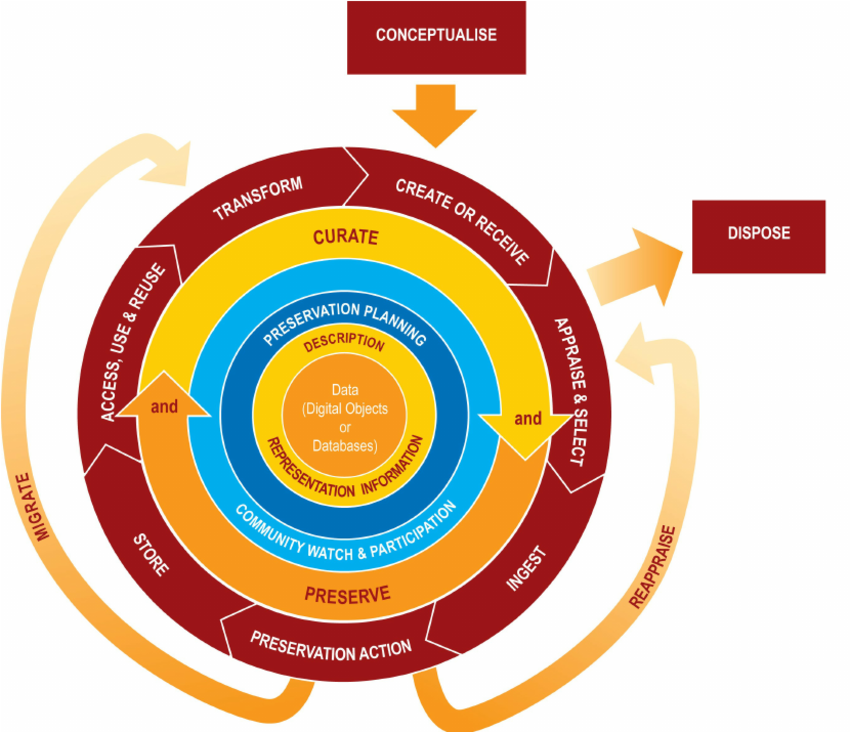
Data curation refers to the stewardship of data throughout its lifecycle. Data does not exist in perpetuity once it is created. In fact, digital assets are far more fragile than most physical artefacts, and are even more vulnerable to deterioration. What is known as the data lifecycle is the sequence of stages that a particular unit of data goes through from its initial generation to its eventual archiving and/or deletion at the end of its useful life. The Digital Curation Centre (DCC) offers a useful ‘Data Curation Lifecycle Model’ which illustrates the cyclical nature of data.
Metadata
Metadata at its most simple is ‘data about data’. It is structured information (that is machine-readable), which makes it possible to describe, locate, or retrieve a digital resource. Metadata enriches a digital resource, and helps make it searchable and findable. Part of data management is having sufficient and clear information describing not only the data but also what has happened to it. In the digital and networked world, metadata is the currency of exchange that enables data to link with other data and researchers. Without metadata, a digital resource or a dataset is almost meaningless.
Repositories require that data/datasets are accompanied by rich metadata, and using established research data repositories like Kikapu makes this process easier.
Broadly speaking, three are three types of metadata:
Descriptive Metadata includes authorship, title, description.
Structural Metadata documents the relationships within and among objects. Structural metadata often links to other components.
Administrative Metadata includes more technical information, including versioning and licensing, for the purpose of research data management.
Different disciplines require different metadata structures, containing different elements and with differing rules and semantics. This is known as a metadata schema. Dublin Core is perhaps the most well-known metadata standard. A comprehensive directory of metadata standards can be found at the Research Data Alliance Metadata Directory.
Metadata is not the same as documentation, although they both provide context and essentially tell the story of the data for users and aid reuse of that data. The main difference is that metadata is structured information, which aids discovery.
Reproducible Research
Reproducible research refers to the ability to reproduce (as closely as possible) the exact processing environment used to generate data. Often, these environments are very sophisticated, and require many moving parts, including version control and different operating systems.
In order to ensure transparency, reproducibility, and reusability, scholarly digital research objects—from data to analytical pipelines—benefit from the application of the principles of reproducible research. This means that all components of the research process (workflow or pipeline) must be shared and made available.
RDM at UWC
UWC’s RDM Policy was approved in March 2021
Other relevant policies:
UWC’s Open Access Policy
The ilifu cloud computing research facility policies and guidelines
The South African Protection of Personal Information Act (POPIA)
The General Data Protection Regulation (GDPR) (EU legislation)
UWC’s RDM specialists, both in the eResearch Office and the Library, can be contacted at rdm-support@uwc.ac.za