

What is Data?
Research data is more specific than just ‘data’, which is the foundation of information and knowledge. Data is integral to us and to society: it not only underpins knowledge-making, but also operations, policy, and decision-making across governments, businesses, and civil society. Data plays an essential role in our day-to-day lives.
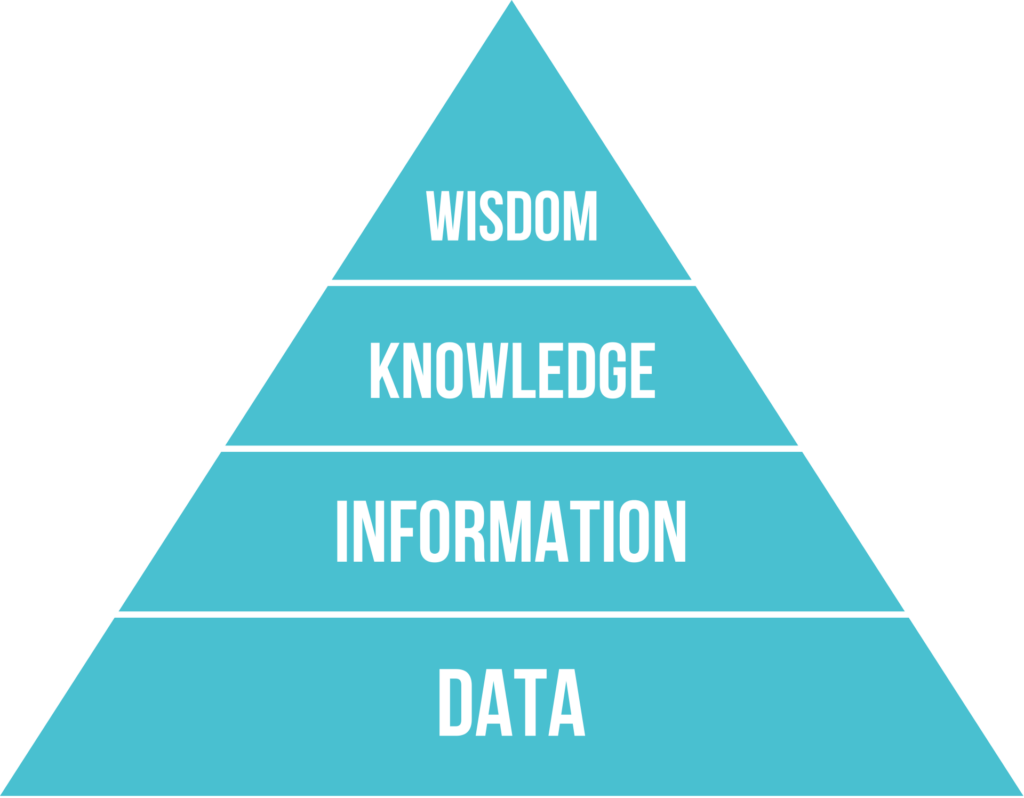
Data is unrefined information in its most basic form, and it needs expertise to draw value from it. On its own, data does not necessarily have meaning – it needs to be processed, which is why it forms the basis for information, knowledge and wisdom.
What is Research Data?
Research data varies widely across faculties and disciplines, but put most simply, research data is simply any information or data that has been collected, observed, generated or created for the sake of research. This includes data that is derived from observation, experiment, interviews, testing hypotheses, surveys etc. Importantly, research data can be qualitative or quantitative, and although many people automatically associate the term with the sciences, research data are collected and used in scholarship across all academic disciplines. Research data is increasing viewed as an important scholarly output.
Today, the term usually refers to digital information, but it can also include non-digital formats (notebooks, diaries, sketches). Research data are not just spreadsheets of numbers; they can take many formats, from video and photography to artefacts and diaries. Scholarly research is increasingly data-driven, and this applies across the board, whether it’s an artist generating images and sounds or a psychologist collecting survey and interview data in order to understand human behaviours. Research data may be experimental data, observational data, operational data, third-party data, public sector data, monitoring data, processed data, or repurposed data. Research data are data that are used as primary sources to support research and that are commonly accepted in the research community as necessary to validate research findings and results.
The Research Lifecycle
The research lifecycle shown below demonstrates a simplified version of how data fits into the research lifecycle. The process of research follows a sequential path, starting with idea discovery, or the generation of a hypothesis.This is followed by an approval stage, where researchers look for funding and get necessary approval/s. Next is doing the research, followed by dissemination. After dissemination, new ideas will be formed, and the cycle begins again.
Importantly, it is not only at the ‘active research’ stage of the lifecycle where data fits into the picture, even though that may be when most of the raw or primary data will be generated. Data is actually present at every step of the research lifecycle.
The Research Data Lifecycle
The Research Data Lifecycle is another simplified model that demonstrates the sequential nature of the cycle of research data, from Planning Research (at the top), and moving clockwise, to Re-Using Data.

Research Planning
At the outset of a research project, researchers need to start planning for the management of their data. This includes a proposal, conceptualising paradigmatic approaches and methodologies as well as costs.
This is also where Data Management Planning begins. Researchers would begin work on their DMP (data management plan) here. These are documents encourage researchers to be upfront about research data plans, and to specify:
- what data will be produced
- that methodologies will be used for data collection
- plans for storage
- plans for access
- plans for preservation
- documentation
- restrictions
- ethics and IP
- costs
Collecting Data and Processing and Analysing Data
The ‘active research’ stage takes place over the second and third phases here, and includes collection, processing and analysis.
These stages of the research process include:
- Using local storage that is secure and reliable (with regular backups)
- Using file formats that are widely used, and where possible, formats that are non-proprietary and open
- Using a file naming convention and folder structure that is logical, and using versioning that are descriptive and consistent
- Including descriptive metadata
Sharing and publishing data
This is where using a repository (like Kikapu) becomes relevant. At this stage, data is to be deposited to an appropriate repository. This includes:
- Anonymising if needed
- Defining access T&Cs
- Identifying embargo periods
- Choosing a license that is as open as possible
Long term storage and preservation of data
At this stage, the researcher is looking after their research data in the long term. This includes:
- Choosing which data to retain (doesn’t need to be anything)
- Choosing a logical and secure home that will ensure accessibility and preservation, authenticity and integrity over time
- Migrating to newer formats if/when needed
- Defining retention/reappraisal schedules
- Arranging disposal if/when necessary
Discovery, Reuse and Citation
This stage determines the longer-term meaning and effect of the research data. It includes:
- Assigning a unique identifier
- Tracking access
- Providing recommending citations
- Provenance metadata (transformed dataset)
- Re-appraising data at end of retention period